
Decoding the O1 Architecture
A Speculative Interpretation behind "Thinking" in OpenAI's O1

Before diving into the details, it's important to emphasize that I have no inside knowledge or understanding of OpenAI's O1 architecture beyond what has been publicly disclosed. This article presents a speculative interpretation of how O1 might work based on the sparse information available and my understanding of related technologies. The diagram below illustrates this interpretation, which is purely hypothetical and intended to stimulate discussion and exploration.
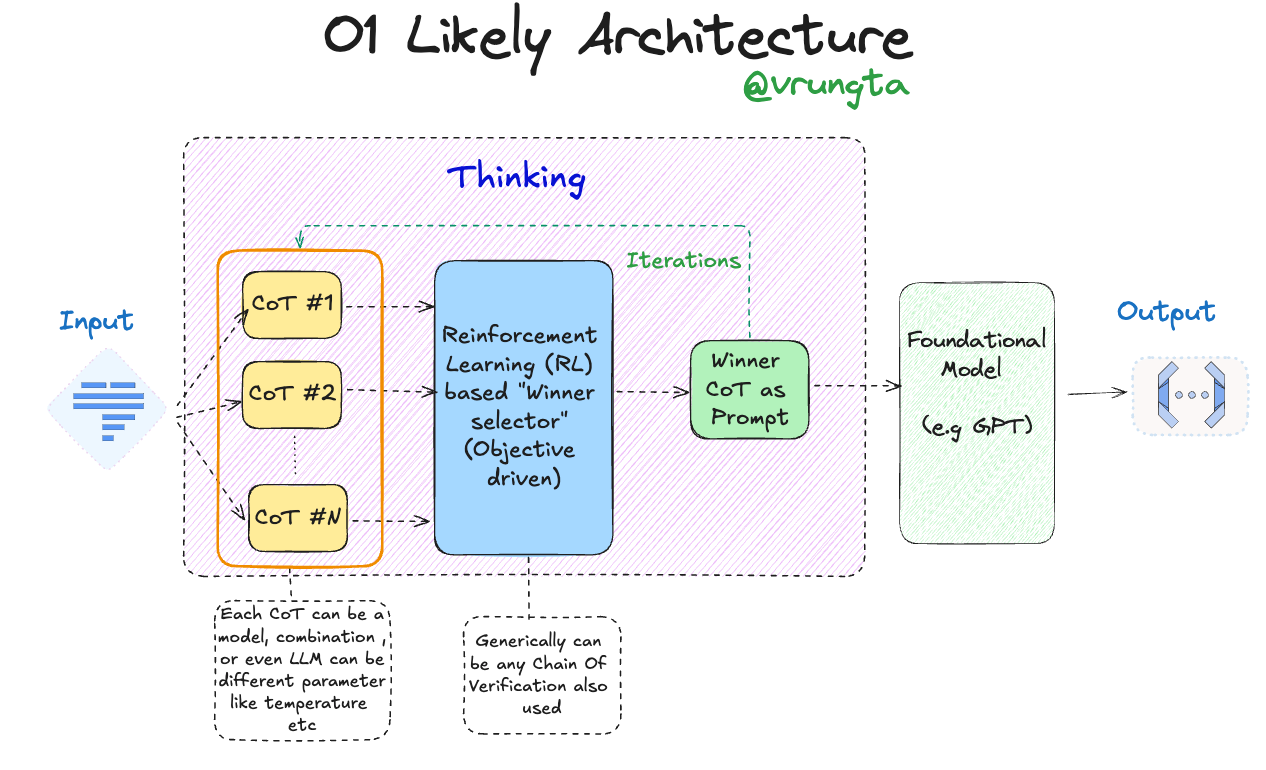
The Diagram: An Overview
The diagram represents a potential architecture for O1, which I envision as a sophisticated system combining Chain of Thought (CoT) reasoning with Reinforcement Learning (RL). The architecture can be broken down into three main components:
Input:
The process begins with an input, typically a prompt or a question. This input serves as the initial stimulus that the system will use to generate multiple potential solutions or paths of reasoning, referred to as Chains of Thought (CoTs).
Thinking (CoT Generation and Selection):
Chain of Thought Generation: The system generates multiple CoTs (CoT #1, CoT #2, …, CoT #N) using Large Language Models (LLMs). These CoTs could be generated by the same or different models, which might vary in terms of architecture, temperature settings, or other parameters. The goal here is to create a diverse set of reasoning paths that can be evaluated for effectiveness.
Reinforcement Learning (RL) Based "Winner Selector": This is the core of the speculative architecture. The generated CoTs are passed through an RL-based module that acts as a "Winner Selector." This module evaluates each CoT based on a predefined objective, selecting the one that is most likely to lead to the desired outcome. The selected CoT becomes the "winning" path, which is then used to continue the reasoning process.
Generic Verification: While the diagram does not delve deeply into this aspect, it's possible that some form of verification or validation process is employed to ensure the selected CoT aligns with the objective, possibly involving additional chains of verification or other techniques.
Output:
Foundational Model (e.g., GPT): The "winning" CoT serves as a prompt for a foundational model, such as GPT. This model takes the selected CoT and uses it to generate the final output, which is presented as the system's response to the original input.
Speculation on How This Might Work
Given that the architecture is speculative, I'll walk through how I imagine this process might work in practice:
Chain of Thought Generation as Moves:
Drawing an analogy with AlphaGo, where moves are actions taken in a game of Go, I speculate that the "moves" in this architecture are the CoTs generated by LLMs. Each CoT represents a potential reasoning path that the system can take to address the input.
Reinforcement Learning for Selection:
The RL component likely plays a crucial role in evaluating the generated CoTs. The success or failure of each CoT is determined based on how well it leads to the correct or desired outcome. Over time, the RL algorithm learns to assign credit or blame to the CoTs based on their contribution to the final result. This learning process allows the system to improve its CoT generation and selection over time.
Inference and Rollouts:
During inference (i.e., when the system is generating a response in real-time), I speculate that the system might perform rollouts, similar to the way AlphaGo evaluates potential moves. This means that the system could simulate different CoTs and their outcomes before selecting the best one. The longer the rollout, the more refined the final CoT, but this also increases the time required to generate a response.
Corollaries and Implications
Assuming this speculative architecture is somewhat accurate, a few key implications arise:
Enhanced Learning from Data:
This approach could potentially offer better performance than simple fine-tuning on synthetic data by leveraging the RL-based CoT selection process. This is akin to the difference between behavior cloning and reinforcement learning in AI.
No Guarantees of Correctness:
While this architecture might improve the probability of generating correct responses, it does not guarantee correctness. This could be a significant limitation for applications requiring high levels of accuracy and reliability.
Inference Speed vs. Accuracy:
The trade-off between the depth of rollouts during inference and the time taken to generate a response could be a critical consideration. Users might be unwilling to wait long for a response, particularly if the accuracy gains are marginal.
A Shift in the Nature of LLMs:
If O1 employs an architecture like the one described here, it would represent a significant departure from traditional LLMs, which rely primarily on next-token prediction. This speculative architecture suggests a more complex and deliberative reasoning process, albeit without guarantees of correctness.
Conclusion
Again, I must emphasize that this article is purely speculative and based on limited public information. The diagram and accompanying explanation represent one possible way that O1 might be architected, but the reality could be quite different. Nonetheless, I hope this exploration sparks further discussion and curiosity about the exciting possibilities in the field of AI and LLMs.
As always, I welcome feedback and insights from others who are exploring this fascinating area. Let's continue to learn and speculate together!