
LLM Chaining: A Pragmatic Decision Framework
Designing LLM Applications: The Pragmatic Case For and Against Chaining
The excitement around Large Language Models (LLMs) is palpable, and teams are rapidly moving from experimentation to building real-world applications. Yet, as we push beyond simple prompts, a critical design question quickly surfaces: should we orchestrate multiple LLMs in a chain, or can a single, well-prompted model suffice?
This isn't an abstract architectural debate; it's a pressing decision with immediate, tangible impacts on performance, cost, user experience, and the sheer maintainability of your LLM-powered systems. Get it right, and you unlock specialized capabilities and efficiency. Get it wrong, and you risk building a brittle, expensive, and debug-heavy 'Rube Goldberg machine' of AI. This article provides a pragmatic decision framework for navigating this crucial choice, helping you decide when to chain and when the simpler path is the wiser one.
Many teams, eager to leverage the perceived strengths of different models, jump to chaining. Others, wary of added complexity, try to centralize intelligence in a single model. This article aims to provide a structured way to think about this decision, focusing on when chaining is a sensible engineering choice and when it might introduce more problems than it solves.

The Core Rationale for Chaining: Specialization and Control
The primary argument for chaining LLMs is specialization. Different models, or even the same model with different prompts and configurations, can be optimized for distinct sub-tasks. For example:
A smaller, faster model for initial input classification or data extraction.
A powerful reasoning model for complex analysis or synthesis.
A fine-tuned model for domain-specific content generation.
A dedicated model (or even non-ML component) for validation or safety checks.
By breaking down a complex task, chaining can theoretically lead to:
Improved Accuracy & Relevance: Each model focuses on what it does best.
Reduced Hallucinations: Narrower scope for each LLM might limit opportunities for ungrounded generation.
Potentially Better Cost-Performance: Using cheaper models for simpler sub-tasks.
Enhanced Modularity and Testability: Isolating components can simplify development and debugging if interfaces are well-defined.
However, these benefits are not guaranteed and come at a price.
The Hidden Costs of Chaining: Increased System Complexity
Chaining LLMs fundamentally means building a more complex distributed system, even if all models run on the same infrastructure. Each "hop" in the chain introduces:
Latency: Network calls, model inference times, and data transformations accumulate.
Operational Overhead: Managing multiple model deployments, versions, and configurations.
Debugging Challenges: Pinpointing errors or performance bottlenecks across a sequence of models is significantly harder. If one model in the chain outputs an unexpected result, how does that propagate, and where did it originate?
Error Propagation & Cascading Failures: The output of one LLM is the input of the next. Errors or undesirable behaviors can compound. A failure in one component can bring down the entire sequence unless robust error handling and fallbacks are implemented.
Interface Management ("Contracts"): The data schema between LLMs needs to be rigorously defined and maintained. Changes in one model's output format can break downstream models.
Therefore, the decision to chain should not be taken lightly. Start by assuming a single model is sufficient, and only introduce chaining when the limitations of a single model are clearly identified and the benefits of chaining demonstrably outweigh the added system complexity.
Decision Framework: When to Consider Chaining
Here are key factors to evaluate when considering a chained LLM architecture:
1. Task Decomposability & Necessity for Specialization:
Is the overall task clearly divisible into discrete sub-tasks where different specialized capabilities are required? For example, a task involving image understanding, then natural language reasoning, then code generation inherently points to multi-modal, specialized components.
Does a single model demonstrably struggle with one specific sub-task, even with sophisticated prompting (e.g., few-shot, chain-of-thought) or retrieval augmentation (RAG)? Quantify this struggle. If a generalist model is 70% effective on sub-task A but 95% on sub-task B, is a specialist for A justified by the overall system improvement?
2. Stringent Requirements on a Sub-Task:
Accuracy & Verifiability: If a particular step requires extremely high factual accuracy or involves verifiable claims (e.g., extracting specific legal clauses, checking medical facts), a specialized, possibly smaller and fine-tuned LLM, or even a non-LLM lookup/verification step, might be necessary as part of a chain.
Safety & Compliance: For tasks requiring PII redaction, content moderation for harmful outputs, or adherence to specific regulatory guidelines, a dedicated model or filter in the chain is often a prudent design choice. This isolates the safety mechanism.
Structured Output for System Integration: If a step must produce perfectly formatted JSON or follow a rigid schema for a downstream non-LLM system, an LLM dedicated and prompted for that specific output format might be more reliable than trying to coerce a general-purpose LLM.
3. Economic Viability & Performance Constraints:
Cost Optimization (The "Cascade"): Can a significant portion of requests be handled adequately by a much cheaper/faster LLM, with more expensive models reserved for complex edge cases? This "cascade" or "filter-and-escalate" pattern is a common driver for chaining.
Latency Budgets: While chaining adds latency per hop, paradoxically, it could reduce overall latency if a small, fast model can quickly dismiss or handle simple tasks, preventing them from consuming resources on a slower, larger model. However, the default assumption should be that chaining increases end-to-end latency.
4. Multi-Modal Workflows:
This is often a non-negotiable reason for chaining. If your application needs to process text to generate images (Text → Image Model), then have another LLM describe or analyze that image (Image Model → Text Model), chaining is inherent.
The "SPLIT" Scorecard (System Perspective):
For each potential split, consider these (adapted from the original article, with a systems lens):
Specialist Gain: Is the performance uplift from a specialized model substantial and critical for this specific step, justifying the integration overhead?
Precise Interface: Does this step require or produce a strictly defined data schema that a generalist model struggles to adhere to consistently?
Lifecycle Cost: What is the total cost (development, deployment, monitoring, latency, inference) of adding this hop versus the benefit gained? Does it simplify or complicate long-term maintenance?
Isolation Benefit: Does isolating this step provide significant advantages in terms of safety, security, compliance, independent testing, or focused iteration?
Tolerable Overhead: Can the system tolerate the added latency, potential points of failure, and debugging complexity associated with this specific hop?
If you're not hitting high scores on these system-level considerations, a single, well-engineered model interaction might be the more robust path.
Common Architectural Patterns for Chained LLMs

If chaining is deemed necessary, consider these established patterns:
Sequential Pipeline:
LLM1 → LLM2 → LLM3. Each model processes the output of the previous one. Simple to conceptualize, but prone to error propagation. Often used for multi-stage transformations (e.g., Summarize → Extract Entities → Translate).
Cascade / Filter & Escalate:
Small/Fast LLM → [Conditional Logic] → Large/Powerful LLM. A common pattern for cost/latency optimization.
Router / Dispatcher:
Input → Classifier LLM (or logic) → [LLM_A | LLM_B | LLM_C]. Directs input to specialized models or sub-chains based on characteristics of the input.
Agentic Loops (e.g., ReAct, Tool-Augmented LLMs):
Planner LLM → [Tool Execution | Specialized LLM Call] → Observer LLM (or Planner updates state) → Loop. More dynamic; an LLM orchestrates calls to tools or other LLMs to achieve a goal. This often involves chaining implicitly.
Self-Correction / Refinement Loops:
Generator LLM → Critic LLM → Generator LLM (with feedback). Improves output quality iteratively. The "critic" can be the same LLM with a different meta-prompt.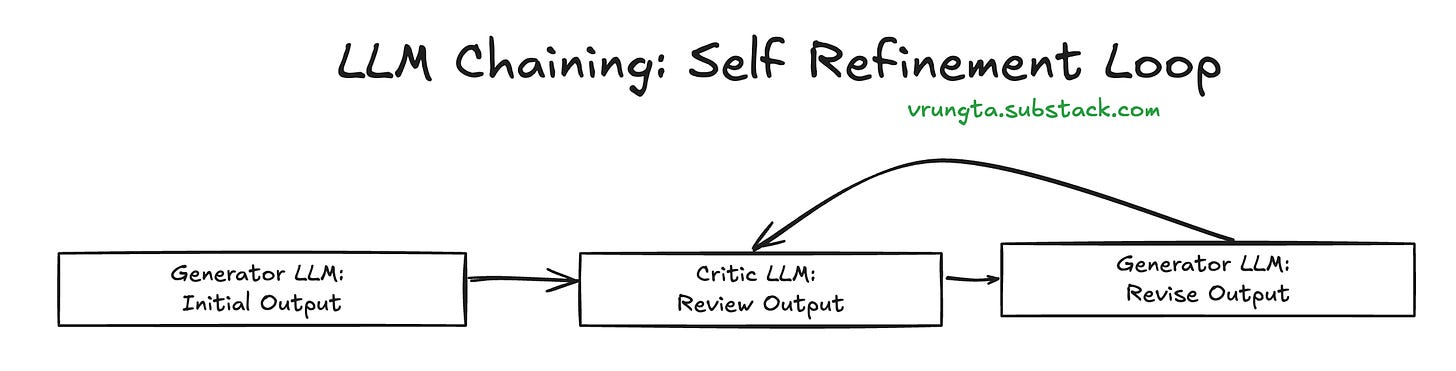




Essential Infrastructure for Chained LLM Systems
If you commit to chaining, you are committing to building a more sophisticated ML system. These are not optional:
Clear Interface Contracts: Use rigid schemas (e.g., JSON Schema, Pydantic models) for data passed between LLMs. Validate inputs and outputs. This is your first line of defense against cascading errors.
Robust Observability:
Logging: Log inputs, outputs, prompts (if permissible), latencies, and token counts for each step in the chain.
Tracing: Implement distributed tracing to understand the flow and pinpoint bottlenecks across the chain.
Monitoring & Alerting: Monitor the health, performance, and output quality of each component. Set up alerts for anomalies, errors, or drift.
Centralized Configuration Management: Manage prompts, model versions, and parameters for each LLM in the chain systematically.
Error Handling & Fallbacks: Define behavior for when a model in the chain fails, times out, or returns unexpected output. Should the chain halt? Fallback to a simpler response? Retry?
Testing Strategy: Develop strategies for unit testing individual LLM components (given an input, does it produce a plausible output format/content?) and integration testing the entire chain. This is non-trivial for stochastic systems.
Concluding Thoughts: Start Simple, Scale with Evidence
The allure of building intricate chains of LLMs can be strong. However, complexity is a debt that accrues interest rapidly in software systems.
Always begin with the simplest architecture that can plausibly meet the requirements. Often, this is a single, well-prompted LLM, perhaps augmented with a robust retrieval system (RAG).
Only introduce chaining when you have clear evidence—quantitative metrics, specific failure modes of a single-model approach, or non-negotiable requirements (like multi-modality or isolated safety checks)—that justify the added system complexity.
If you chain, invest heavily in the infrastructure and practices outlined above. Treat it as a distributed system, because that's what it is.
Iterate and measure. Continuously evaluate if each component in your chain is adding sufficient value to justify its existence and its operational cost. Be prepared to simplify or refactor if it isn't.

Building robust LLM applications is as much about thoughtful system design and operational discipline as it is about the models themselves. Chaining is a powerful tool in your toolkit, but like any powerful tool, it requires skill, judgment, and a clear understanding of its implications.
Finally, remember that the LLM landscape is dynamic. The optimal level of chaining today might change tomorrow. As foundation models become more capable of multi-tasking complex instructions, or as specialized models become even more efficient, revisit your chained architectures. The goal is not to build complex chains for their own sake, but to build effective, maintainable systems that can evolve. What requires three chained models today might be elegantly handled by two, or even one, in a future iteration.
Appendix: Illustrative Case Studies in LLM Chaining
To further illustrate the practical application of the decision frameworks and architectural patterns discussed, let's examine a couple of common scenarios where LLM chaining is often employed.
Case Study 1: Customer Support Automation
Scenario Overview:
Automating customer support often involves a multi-step process to understand a user's query, retrieve relevant information, formulate a helpful response, and ensure the response is safe and compliant. Attempting this with a single monolithic LLM can lead to challenges in speed for simple queries, cost inefficiency, unreliable safety adherence, or suboptimal information retrieval.
Applying the Article's Framework & Design Choices:
Initial Justification for Chaining:
Task Decomposability: The workflow naturally breaks into: 1. Intent Recognition, 2. Information Retrieval, 3. Response Generation, 4. Safety/Compliance Checks.
Necessity for Specialization:
Intent: Requires speed and accuracy on potentially a defined set of common user needs.
Retrieval: Best handled by dedicated search tools or vector databases.
Synthesis: Needs strong reasoning and natural language generation.
Safety/PII: Requires high precision; specialized models/tools are more reliable and auditable.
Economic Viability (Cascade Principle): A small, fast LLM for initial, high-volume intent classification is more cost-effective than using a large model for every query. The large model is reserved for the more complex synthesis task.
Stringent Requirements: Adherence to PII policies and providing safe, non-harmful responses are non-negotiable, justifying dedicated filtering steps.
Chain Architecture & Component Choices:
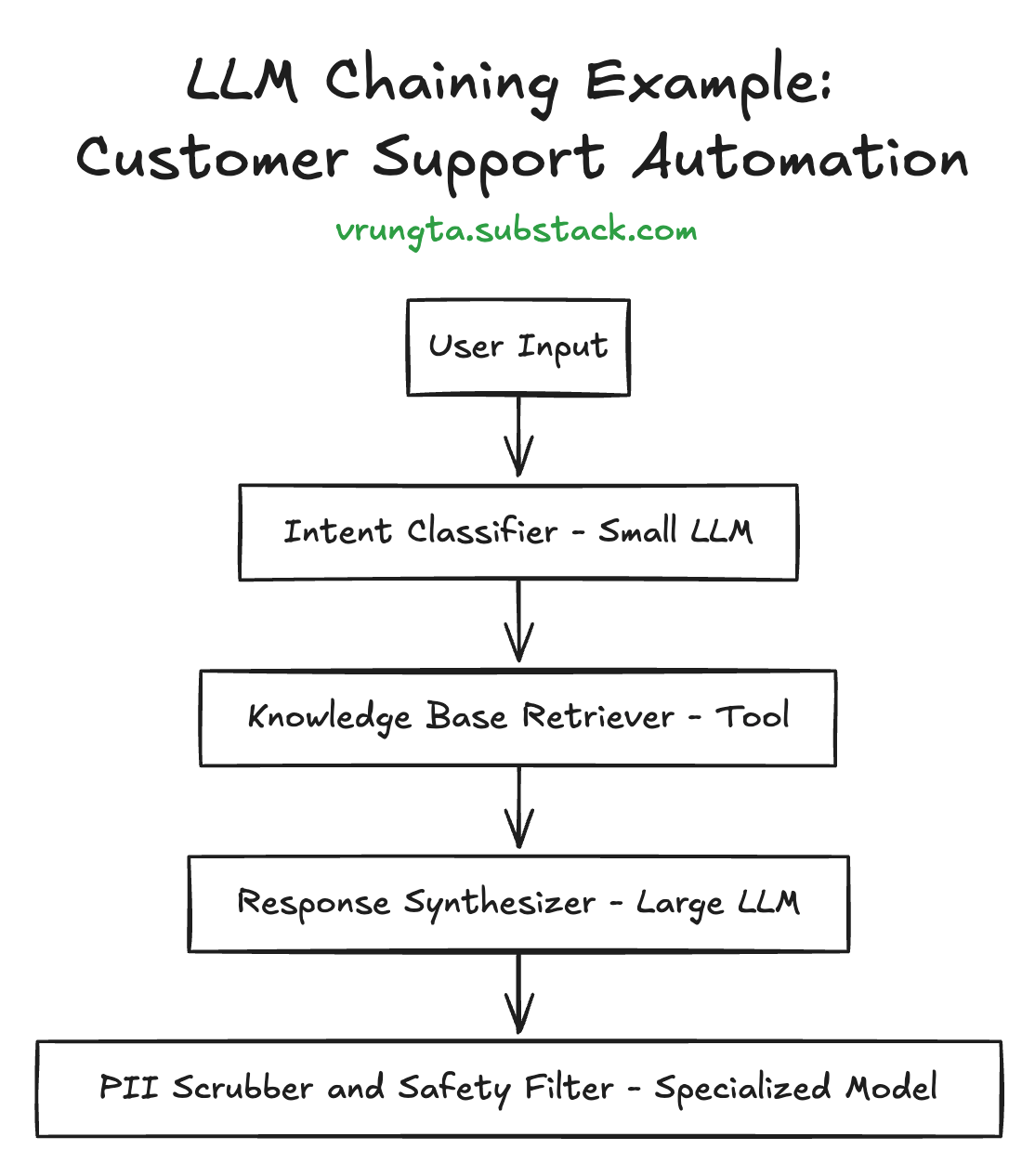
Overall Pattern: This is primarily a Sequential Pipeline with integrated Tool Use.
Step-by-Step Breakdown:
A. User Input: Raw text query from the customer.
B. Intent Classifier (Small LLM):
Task: Identify user's primary goal (e.g., "billing query," "technical issue") and extract key entities.
LLM Type Considerations: A smaller, fast model optimized for NLU/classification tasks. This could be a distilled version of a larger foundation model or one specifically fine-tuned on common support intents. The key drivers are low latency and lower cost per inference for this high-volume entry point.
Output: Structured data (e.g., JSON) defining the intent and entities, forming a clear interface contract for the next step.
C. Knowledge Base Retriever (Tool):
Task: Fetch relevant FAQs, documentation, or user data based on the classified intent.
Tool Type Considerations: Vector database for semantic search, traditional keyword search, or a hybrid. This is not an LLM generation task but an information retrieval task.
D. Response Synthesizer (Large LLM):
Task: Generate a coherent, helpful, and contextually appropriate response using the original query and retrieved knowledge.
LLM Type Considerations: A powerful, general-purpose reasoning and instruction-following LLM with strong natural language generation capabilities. This is where the bulk of the "intelligence" for response quality resides. Its higher cost is justified by its application to pre-filtered and context-enriched queries.
E. PII Scrubber & Safety Filter (Specialized Model/Tool):
Task: Detect and remove/anonymize Personally Identifiable Information (PII). Check for adherence to safety guidelines, brand voice, and company policies.
Model/Tool Type Considerations: Could be a smaller LLM fine-tuned specifically for PII detection and content policy classification, rule-based systems (e.g., regex for PII), or a dedicated third-party content moderation API. The isolation benefit of this specialized component is crucial for compliance and focused updates.
Key System & Operational Considerations (Applying Article's Learnings):
Interface Contracts: Rigorously defined data schemas between each component are critical. For example, the output format of the Intent Classifier must be precisely what the Knowledge Base Retriever expects.
Observability: Essential to monitor latency per hop, accuracy of intent classification, relevance of retrieved documents, and the PII scrubber's effectiveness. Tracing a single user request through all stages helps in debugging.
Error Handling & Fallbacks:
Low confidence from Intent Classifier? -> Route to a human or ask for clarification.
Knowledge Base Retriever finds no relevant documents? -> The Response Synthesizer needs a strategy to inform the user gracefully.
PII/Safety filter blocks a response? -> Log for review, potentially escalate to a human if the block appears erroneous or for sensitive cases.
Testing Strategy: Requires unit tests for each component (e.g., intent model accuracy on a test set) and integration tests for the entire chain flow.
This detailed breakdown for customer support automation illustrates how the principles of task decomposition, specialization, economic viability, and stringent requirement handling justify a chained architecture. Furthermore, it highlights the importance of considering the system as a whole, including interface contracts, observability, and robust error handling, as emphasized throughout this article.
Case Study 2: Multi-Modal Content Generation
Scenario Overview:
Creating content that combines text and images (e.g., an illustrated blog post, a product description with visuals, or a children's story) often requires a sequence of generative steps. A single LLM typically cannot handle both sophisticated text generation and direct, high-quality image creation. Chaining different specialized models and tools becomes a necessity.

Applying the Article's Framework & Design Choices:
Initial Justification for Chaining:
Task Decomposability & Necessity for Specialization (Multi-Modal Workflow): This is the primary driver. Text generation and image generation are fundamentally different tasks requiring different types of models. The process further decomposes into: 1. Content Structuring (Outline), 2. Detailed Text Elaboration, 3. Visual Concept Translation (Image Prompts), 4. Image Realization, 5. Final Assembly.
Stringent Requirements (Implicit):
Text Quality: Coherent, well-structured, and engaging text is needed from LLM1 and LLM2.
Image Relevance & Quality: The generated images must align with the text and meet aesthetic standards, which depends heavily on the quality of prompts from LLM3 and the capability of the Image Generation Tool.
Economic Viability: While powerful models are needed, breaking down tasks allows for potentially using different sizes or types of models for different text generation stages. Image generation itself has its own cost structure.
Chain Architecture & Component Choices:
Overall Pattern: A Sequential Pipeline leveraging different LLMs for text-based tasks and a specialized Tool for image generation.
Step-by-Step Breakdown (as per your diagram):
A. User Theme: The initial concept or topic provided by the user.
B. Outline Generator (LLM1):
Task: Take the user theme and generate a structured outline for the content (e.g., sections, sub-points).
LLM Type Considerations: An LLM strong in structuring information, brainstorming, and hierarchical organization. Could be a general-purpose powerful model or one slightly prompted/tuned for content planning.
C. Section Writer (LLM2):
Task: Elaborate on each point in the outline, generating detailed text for each section. This might be called iteratively for each section.
LLM Type Considerations: An LLM with strong creative writing or expository writing skills, depending on the content type. It needs to maintain coherence with the outline and overall theme. Could be the same type as LLM1 or a different one specialized for prose.
D. Image Prompt Generator (LLM3):
Task: Analyze the text generated by LLM2 (for a specific section or concept) and create effective, descriptive prompts suitable for an image generation tool. This is a critical translation step.
LLM Type Considerations: An LLM skilled at understanding visual language, extracting key descriptive elements from text, and formatting prompts in a way that image models understand well (e.g., including style cues, subject details, composition ideas). This might be a smaller, specialized LLM or a powerful general model prompted carefully for this task.
E. Image Generation Tool:
Task: Take the textual prompts from LLM3 and generate visual images.
Tool Type Considerations: A dedicated text-to-image model/API (e.g., DALL-E, Midjourney, Stable Diffusion, or relevant APIs). This is a specialized tool, not an LLM in the same category as the text generators.
F. Content Assembler (Code or LLM4):
Task: Combine the generated text (from LLM1 & LLM2) and images into a final presentable format. This could involve formatting, layout suggestions, caption generation, or simple concatenation.
Component Type Considerations:
Code: Custom scripts for assembling HTML, Markdown, or other document formats, placing images alongside relevant text.
LLM4: A general-purpose LLM could be used to suggest layouts, generate captions for the images based on surrounding text, or ensure a consistent tone in the final assembled content.
Key System & Operational Considerations (Applying Article's Learnings):
Interface Contracts: Crucial between all steps. The outline from LLM1 needs to be consumable by LLM2. The text from LLM2 needs to be effectively processed by LLM3. The image prompts from LLM3 must be suitable for the Image Generation Tool. The format of images and text needs to be handled by the Content Assembler.
Iterative Refinement (Potential): While shown as sequential, a real-world application might involve loops. For instance, if LLM3 generates a poor image prompt, or the Image Generation Tool produces an unsatisfactory image, there might be a loop back to refine the prompt or even earlier text.
Observability: Tracking the quality of outputs at each stage (e.g., coherence of outline, relevance of section text, effectiveness of image prompts, appeal of images).
Error Handling: What if LLM1 fails to generate a sensible outline? What if LLM3 creates prompts that yield nonsensical images? The system needs strategies for retries, alternative prompts, or flagging for human review.
Cost Management: Text LLM calls and image generation API calls have distinct costs. The system design should consider how many images are generated per piece of content, image resolution, etc.
This multi-modal example underscores how chaining is often not just an option but a necessity when combining fundamentally different generative capabilities. Each component plays a specialized role, and the success of the overall system depends on the careful orchestration of these specialists and the clear "contracts" between them.