
Multi-Agent GenAI Systems
Architectural choices & Approaches.

For product managers and architects: Moving from solo LLMs to collaborative agent teams with effective strategies for decomposition and design.
Prologue: The Limits of One and the Promise of Many
The world of Large Language Models (LLMs) is no longer just about single, impressive chatbots. We're rapidly moving towards building sophisticated applications that can tackle complex, multi-step problems. But as our ambitions grow, so do the architectural challenges. How do we best orchestrate these powerful models to achieve goals that are too big, too varied, or too nuanced for a single LLM to handle alone?
TL;DR
(Objective: Guide me on how to think about breaking down tasks and determining agent granularity)
This article guides product managers, developers, and architects in transitioning from simple LLM chains to complex multi-agent systems.
It posits that as AI ambitions expand, a single LLM often becomes a performance bottleneck, thus requiring a "team" of specialized AI agents.
The article explores guiding philosophies for structuring these agent teams, using analogies from organizational design and the monolith-vs-microservices software paradigm.
A core focus is "The Art and Science of Agent Decomposition," which offers a pragmatic framework. This includes identifying symptoms of incorrect agent granularity (too few or too many agents) and providing practical factors for evaluation to help readers in task breakdown and determining the optimal number and roles for agents.
Emphasis is placed on an iterative development approach: starting simple and refining based on evidence.
The article concludes that mastering agent decomposition is crucial for building robust, adaptable, and truly intelligent systems.
Beyond the Assembly Line: When Simple Chains Aren't Enough
Many of us started our journey into complex LLM applications with LLM chaining. In my previous article, 'LLM Chaining: A Pragmatic Decision Framework,' I discussed how chaining is often a "pragmatic first step for task decomposition." Think of it as an assembly line: input flows through a sequence of specialized LLMs, each performing a distinct operation—classify, extract, summarize, translate. This approach is powerful and has allowed us to build more capable systems than a single prompt to a single model ever could. The pragmatic decisions we made about when and how to chain, managing context, and defining interfaces, were crucial learning experiences.
However, these same decisions foreshadow the more intricate choices we face as we push the boundaries further. The linear, often rigid, nature of a simple chain can become a bottleneck.
The Soloist's Struggle: Challenges with a Single, Overburdened Agent
Imagine trying to build an AI system to manage a complex research project: it needs to understand the user's high-level goals, break them down into research questions, search academic databases, read and synthesize papers, identify conflicting information, draft summaries, and even suggest future research directions. While a single, highly capable LLM augmented with Retrieval Augmented Generation (RAG) might attempt this, it quickly runs into what we can call the "soloist's struggle."
The "cognitive load" on that single LLM becomes immense. It's like asking one brilliant individual to be an expert librarian, a critical analyst, a creative writer, and a project manager, all at once, and to switch between these roles flawlessly with every new piece of information. Prompts become incredibly long and convoluted, trying to specify every nuance for every possible sub-task. The model's expertise gets diluted; its ability to maintain deep context on one specific sub-task while juggling others diminishes. Errors creep in, not because the model isn't smart, but because it's being asked to do too many fundamentally different things simultaneously.
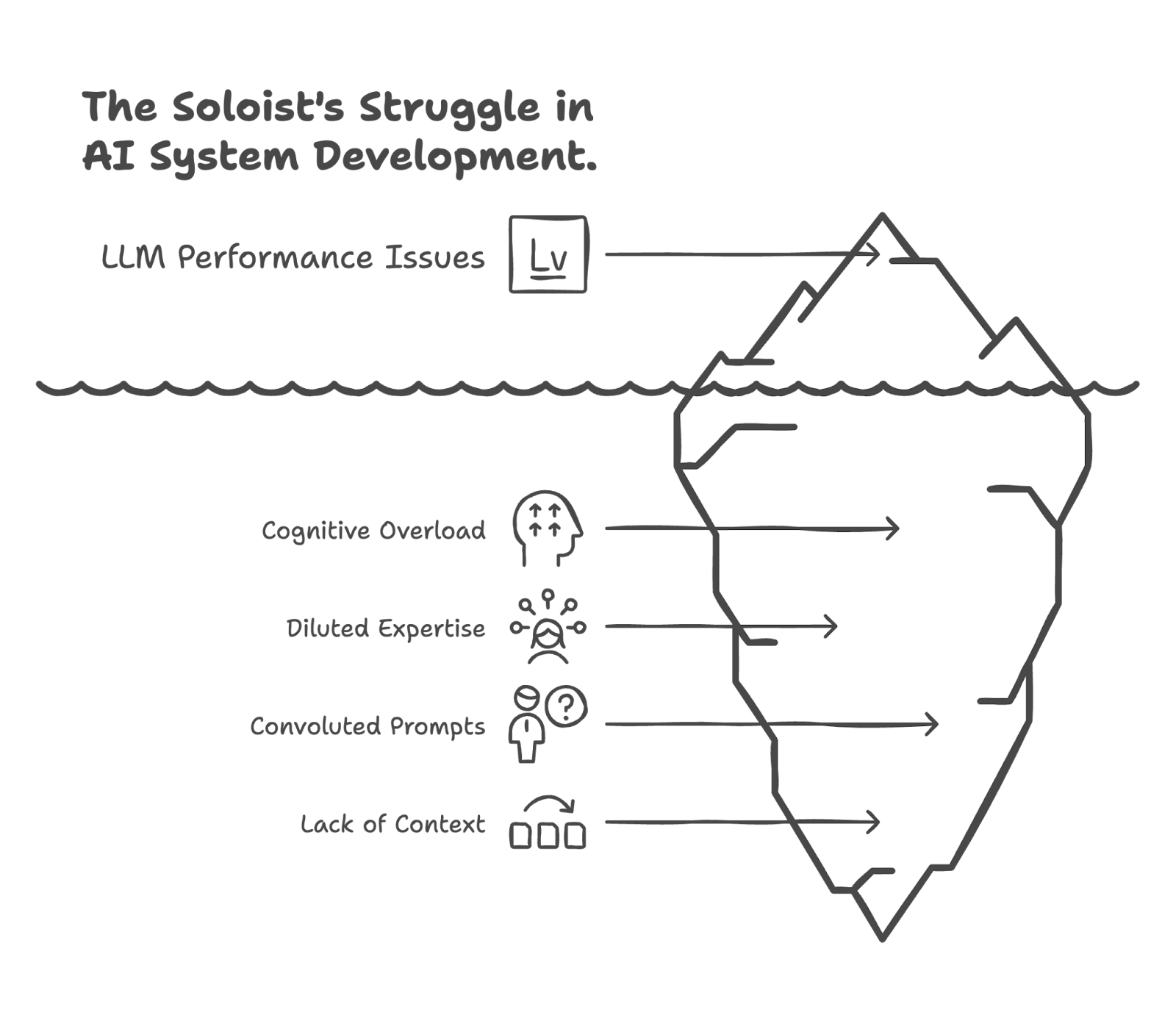
Consider this mini-story: A startup built a "Universal Business Analyst" agent. Powered by the latest LLM, it was designed to ingest company data, market trends, and competitor reports to generate comprehensive strategic recommendations. Initially, for simple scenarios, it worked. But as users asked for more nuanced analyses—like simultaneously evaluating financial risk for a new product line while also drafting marketing copy for it and assessing the HR implications—the single agent began to falter. Its reports became generic, it missed subtle connections, and sometimes it would "forget" constraints from one part of the request when working on another. The prompt became a monstrous, unmaintainable beast. The startup realized their soloist, however talented, was overwhelmed. They needed a new approach, a way to bring specialized focus to different parts of the problem. This is where the concept of a "team" of agents begins to shine.
Introducing "The Team": The Power of Specialized Agents Working in Concert
An agent, in this context, is more than just an LLM call. As outlined in OpenAI's "A practical guide to building agents," it's a system that leverages an LLM for reasoning and decision-making, has access to various tools (APIs, functions, databases) to interact with external systems, and operates based on explicit instructions or goals, often with a significant degree of independence to execute workflows. \
The core idea is simple yet profound: just as human teams, composed of individuals with specialized skills, can tackle far more complex challenges than any single person, a team of specialized AI agents can collaborate to achieve multifaceted goals more effectively and robustly.
The Central Question: How Many Agents, and Who Does What?
Once we embrace the idea of a "team," the immediate and central questions become: How many agents do we actually need? And how do we decide who (which agent) does what? This isn't just about arbitrarily splitting tasks; it's about thoughtful system design to create an effective, efficient, and maintainable collaborative intelligence.
OpenAI's guide provides excellent "early signs you need a team," or when to consider multiple agents:
Complex Logic: Your prompts are becoming nightmarishly long and filled with conditional statements that are hard to manage and debug. \
Tool Overload/Ambiguity: A single agent has access to too many tools, or the tools have overlapping functionalities, making it difficult for the LLM to consistently choose the right one for a given sub-task. \
Need for Distinct Expertise: The overall task clearly requires different, often deeply specialized, skills (e.g., creative writing, data analysis, code generation, image understanding).
Desire for Parallelism/Efficiency: Some sub-tasks can be performed concurrently, and distributing them across multiple agents could speed up the overall process.
Framing the decomposition challenge correctly is paramount. It's not merely about dividing work but about architecting a system where agents can collaborate seamlessly, share information effectively, and contribute their specialized strengths towards a common objective. The rest of this guide is dedicated to helping you answer the "how" of this crucial design process.
Part 1: Guiding Philosophies – How to Think About Agent Structure
Before diving into specific architectural patterns, it's helpful to establish some guiding philosophies. How can we intuitively approach the problem of structuring our agent teams? Two powerful analogies from the world of human organization and software engineering can serve as our "North Stars."
North Star Analogy 1: Learning from Organizational Design
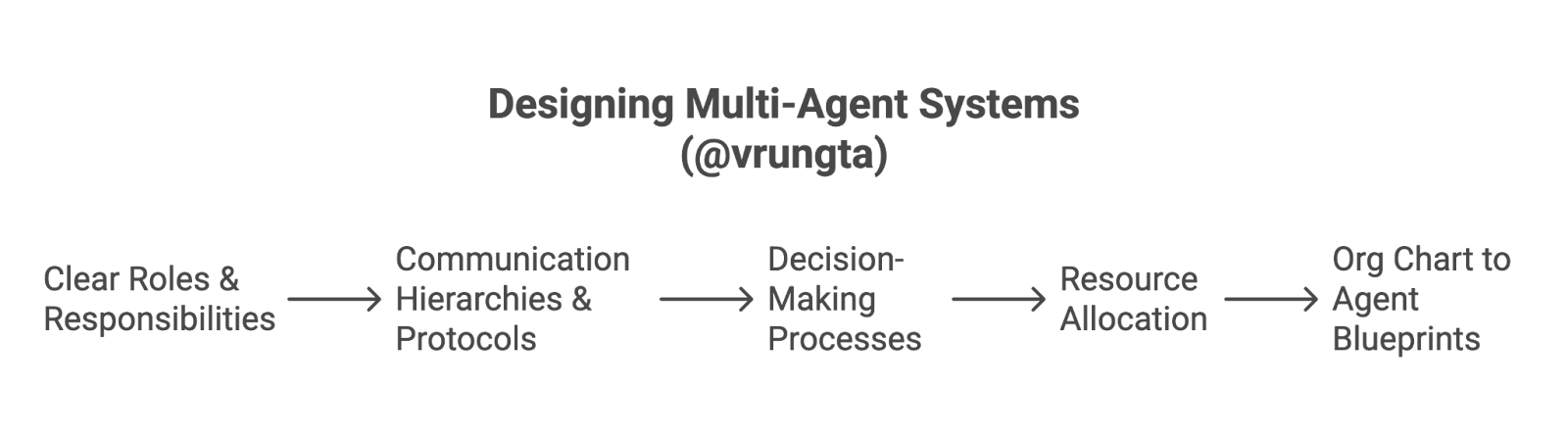
Think about how successful human organizations structure themselves to tackle large-scale projects or run complex operations. We don't expect one person to do everything. Instead, we create departments, teams, and roles, each with specific responsibilities and expertise. We can apply similar principles to designing our multi-agent systems:
Clear Roles & Responsibilities (Agent Specialization): Just as a marketing department differs from engineering, each agent should have a clearly defined purpose and area of expertise. What is this agent uniquely good at? What is its primary responsibility within the larger workflow?
Communication Hierarchies & Protocols: How do teams in a company report progress or request information? Agents, too, need defined ways to communicate—passing data, signaling task completion, or requesting help from other agents. This could be a hierarchical structure (reporting to a "manager" agent) or peer-to-peer.
Decision-Making Processes: Who makes the call when there's a fork in the road? In some agent systems, a central "manager" agent might make key decisions. In others, decision-making might be more decentralized, with agents making local choices based on their specialized knowledge.
Resource Allocation: Which teams get access to which tools or budgets? Similarly, which agent gets access to which specific tools, databases, or even more powerful (and expensive) LLM models?
From Org Charts to Agent Blueprints: Imagine sketching an organizational chart for your AI project. Who are the key "departments" (major functional agents)? Are there "team leads" (orchestrator or manager agents)? What are the specialized "individual contributor" roles (highly focused worker agents)? Asking How does a well-run project team break down its work and coordinate efforts? can provide surprisingly relevant insights for designing your agent system's structure.
North Star Analogy 2: The Monolith vs. Microservices Dilemma
Software engineers have long grappled with the trade-offs between monolithic applications and microservice architectures. This analogy maps remarkably well to the single "super" agent versus multi-agent system decision:
Single "Super" Agent as a Monolith:
Perceived Benefits: Initially, it might seem simpler to put all the logic and capabilities into a single, powerful agent. All the "code" (i.e., the prompt and tool access logic) is in one place.
The Downsides: As the agent's responsibilities grow, the monolithic prompt becomes unwieldy and incredibly difficult to maintain. Debugging is a nightmare because an error in one part of the logic can have unforeseen consequences elsewhere. Scaling specific functionalities (e.g., making just the "data analysis" part faster or more accurate) is hard without impacting the whole. It becomes a single point of failure; if the prompt has a flaw or the LLM misinterprets one complex instruction, the entire system can break.
Multi-Agent System as Microservices:
The Philosophy: Break down the large, complex application into a collection of small, independent, and specialized services (agents). Each agent focuses on doing one thing well.
The Benefits: This promotes modularity. Each agent can be developed, tested, and updated independently. You can scale specific agents based on demand (e.g., if the "image generation" agent is a bottleneck, you can optimize or replicate it without touching the "text summarization" agent). Fault isolation is better; if one agent fails, it might not bring down the entire system, and the scope of the error is easier to pinpoint.
The Costs: This approach isn't free. It introduces orchestration complexity—you now need a way to manage how these agents interact and coordinate their work. There's also communication overhead; agents need to pass messages and data, which can introduce latency and add to the overall cost (e.g., more API calls if agents are remote).
Translating Microservice Principles to Agent Boundaries: When software architects design microservices, they think about concepts like "bounded contexts" (ensuring a service owns its specific domain and data) and "clear APIs" (well-defined interfaces for how services interact). Similar thinking applies to agents. How do you decide the boundaries of a microservice? What defines its specific responsibility and its contract with other services? These questions are directly relevant when deciding how to break down your problem into distinct agents and define how they will collaborate.
By keeping these two North Stars—organizational design and the monolith-microservices paradigm—in mind, we can approach the task of designing multi-agent systems with a richer conceptual toolkit, ready to tackle the specifics of architectures and roles.
Part 2: Designing the Team – Architectures and Roles
With our guiding philosophies established, let's explore common ways to structure our "agent teams" and define their individual roles. The architecture you choose will heavily influence how tasks are decomposed and how agents interact.
Common Team Structures: Architectural Patterns for Collaboration
The OpenAI guide on building agents highlights several orchestration patterns. \ Two of the most fundamental are the Manager-Worker model and the Decentralized model, which can be thought of as different "team structures": \
a) The Manager-Worker Model (Hierarchical Orchestration):
Concept: This is like a traditional project team with a clear leader. A central "manager" agent is responsible for understanding the overall goal, breaking it down into sub-tasks, delegating these sub-tasks to specialized "worker" agents, and then synthesizing their outputs to produce the final result or decide the next overall step. \ The worker agents are, in essence, powerful, intelligent tools for the manager. \
Example: A "Research Report Manager Agent" might delegate literature search to a "Database Search Agent," paper summarization to a "Summarization Agent," and statistical analysis of results to a "Data Analysis Agent." The manager then compiles their contributions into a coherent report.
Implications for Decomposition: This pattern encourages breaking down the main goal into clearly definable sub-goals that can be assigned to specialists. The number of worker agents depends on the distinct specializations needed.
b) The Collaborative Crew (Decentralized Peer-to-Peer Handoffs):
Concept: Here, agents operate more like an assembly line of experts or a series of consultants. There isn't necessarily a single, persistent manager. Instead, an initial agent might handle a task and then "hand off" the workflow (and relevant context) to another specialized agent based on the current state or need. \ This can continue through several agents.
Example: A "Customer Inquiry Triage Agent" receives a user's message. If it's a technical issue, it hands off to a "Technical Support Agent." If that agent needs to access account details, it might query an "Account Info Agent" (which could be a tool or another agent) before formulating a response.
Implications for Decomposition: This pattern focuses on defining clear transition points and criteria for when one agent's responsibility ends and another's begins. Agents are defined by their specific stage in a potential workflow.
c) Hybrid Models:
Concept: Naturally, you can combine these patterns. You might have a "manager" agent overseeing a team of workers, and this entire team might then hand off its collective output to another distinct team or a specialized finalizer agent.
Example: An "Automated Content Creation Manager" oversees a "Writer Agent" that crafts text and an "Image Curation Agent" that sources or generates relevant visuals. Once they produce a draft article with image suggestions, the manager hands it off to an "SEO & Compliance Agent" for final review and optimization.
Story Hook: As you consider these patterns, think about your specific problem. Does it lend itself to a central coordinator, or is it more of a sequential flow of expertise? The choice of pattern will guide how you naturally start to see the "seams" along which your problem can be divided, and thus, how many agents you might need and what their high-level roles will be.
Defining Who Does What: Core Components & Design Principles
Regardless of the overarching architecture, each individual agent in your team needs to be well-defined to be effective.
Anatomy of an Effective Agent (Specialist):
Models: Selecting the right LLM for the job is crucial. As the OpenAI guide suggests, not every task requires the smartest (and often most expensive or slowest) model. \ A simple classification agent might use a smaller, faster model, while an agent responsible for complex reasoning or creative generation might need a more powerful one. \
Tools: Each agent should have access to a curated set of tools (APIs, functions, databases) that are directly relevant to its specialized role. \ Giving an agent access to unnecessary tools increases the chance of it making incorrect choices.
Instructions (Prompts): This is where the agent's role, responsibilities, persona, and constraints are explicitly defined. \ For multi-agent systems, instructions also need to cover how an agent should interact with other agents, what format its output should take for downstream agents, and how it should handle information received from others. High-quality instructions are paramount for predictable and reliable agent behavior. \
Key Design Principles for a Cohesive Team:
Drawing inspiration from best practices in software engineering and insights from organizations like Anthropic on building effective agents, consider these principles:
Clear Role Definition & Specialization (Crucial for decomposition!): This cannot be overstated. Each agent should have a distinct, well-understood purpose. Avoid creating "jack-of-all-trades" agents within your multi-agent system, as that recreates the monolith problem at a smaller scale. For instance, within a customer support system, rather than one generic "Support Agent," you might have a "Query Understanding Agent," a "Knowledge Retrieval Agent," a "Solution Formulation Agent," and a "PII Redaction Agent," each highly specialized. Other examples could include a "Data Validation Agent" ensuring input quality across a workflow, a "User Sentiment Analysis Agent" to tailor responses, or a "Content Variant Generation Agent" for A/B testing marketing copy.
Standardized Communication Interfaces: How will agents pass data and control to each other? Define clear, consistent formats (e.g., JSON schemas) for messages and outputs. Think of these as the "API contracts" between your agents. Importantly, these interfaces should be treated with the same rigor as microservice APIs, including versioning and clear contracts, to prevent cascading failures when one agent is updated and to enable independent evolution of agents.
Effective Task Decomposition (This is the goal!): The overall problem must be broken down into sub-tasks that are appropriate for individual agents. This decomposition should align with the specialized roles you've defined.
Context Management: Decide how much information and history each agent needs to perform its task. Passing too little context can lead to errors; passing too much can be inefficient or overwhelming.
Error Handling and Resilience: What happens if an agent fails, produces an unexpected output, or a tool it relies on is unavailable? The system needs strategies for retries, fallbacks to alternative agents or simpler responses, or escalation to human intervention. \
Observability and Debugging: Multi-agent systems can be complex to monitor. You'll need robust logging, tracing (to follow a request across multiple agents), and monitoring to understand system behavior, pinpoint bottlenecks, and debug issues.
By focusing on these architectural patterns and design principles, you can start to sketch out not just that you need a team, but what that team looks like, who's on it, and how they'll work together. This lays the groundwork for the critical next step: the art and science of deciding just how fine-grained your agent decomposition should be.
Part 3: The Art and Science of Agent Decomposition – Finding the Right Fit
We've established why we might need multiple agents and explored high-level philosophies and architectures for structuring them. Now we arrive at the heart of the matter for anyone wanting to build these systems: How do I actually decide how to break down my problem? How many agents is the "right" number? This is where the "art" of system design—drawing on intuition, domain expertise, and creative problem-solving—meets the "science" of pragmatic evaluation using structured frameworks.
The "How Many Agents?" Question: A Pragmatic Framework
The decision to decompose a task across multiple agents isn't arbitrary. It's driven by the desire to achieve tangible benefits. Many of these were highlighted in my previous article on LLM chaining and become even more critical in multi-agent systems. These key drivers are:
Accuracy: Decomposition helps achieve higher quality and more relevant outputs by allowing agents to specialize on narrower tasks where they can perform better.
For your product, this means: More reliable functionality, leading to increased user trust, higher task completion rates, and greater overall satisfaction.
Simplicity: It makes individual agents easier to develop, understand, and debug by reducing the complexity of their prompts and narrowing their focus.
For your product, this means: Faster development cycles for individual features managed by agents, quicker bug fixes, and a more maintainable codebase for the AI system.
Cost: This approach allows for optimization of resource use and can potentially reduce overall expenses by strategically using different models (e.g., cheaper/faster ones for simpler tasks).
For your product, this means: Potentially lower operational expenses, which can influence pricing strategy, enable more accessible features, or improve the overall ROI of the AI investment.
Safety & Compliance: Decomposition helps reduce risks and improve adherence to guidelines by isolating sensitive operations or compliance checks into dedicated, auditable agents. \
For your product, this means: Enhanced security for user data, better adherence to regulatory requirements, and a more trustworthy platform, reducing reputational and legal risks.
Flexibility: It makes the overall system easier to modify, adapt to new requirements, and adjust its scope or scale over time.
For your product, this means: The ability to rapidly iterate on specific functionalities, respond more quickly to market changes, or add new, distinct capabilities without requiring a massive overhaul of the entire system.
Privacy: This enhances the protection of sensitive information by isolating PII-handling agents, enabling targeted privacy controls, and improving auditability of data access. \
For your product, this means: Stronger user data privacy, easier demonstration of compliance with privacy regulations, and increased user confidence in how their information is handled.
Starting Point: The "Single Responsible Agent" Fallacy
It's tempting to think that the most advanced LLM should be able to handle everything if prompted cleverly enough. However, as discussed in the Prologue (the "Soloist's Struggle"), trying to make one agent responsible for too many disparate or complex functions is often a trap. The prompt becomes a fragile, convoluted monolith, and the agent's performance degrades. Recognizing this "fallacy" is the first step towards effective decomposition.
Iterative Decomposition: You Don't Need to Get it Perfect on Day One
The principle of "Start Simple, Scale with Evidence," emphasized in the context of LLM chaining, is equally vital here. You might begin with a coarser-grained decomposition—perhaps just two or three agents handling major functional blocks. As you build, test, and observe, you'll identify areas for refinement. This refinement might be triggered by observing specific performance bottlenecks with one agent, realizing an agent's prompt has grown overly complex and brittle, identifying that an agent is struggling to choose between too many diverse tools, or when new requirements emerge that demand a more specialized skill set not cleanly fitting into existing agents. Agent decomposition is often an iterative process of observing, evaluating, and adjusting. The "art" here lies in recognizing these triggers and having the intuition to explore different boundary definitions.
Finding the Sweet Spot: Evaluating Agent Granularity (The Core "How-To")
Determining the ideal number of agents—the "granularity" of your decomposition—is about striking a balance. There's a central trade-off:
Benefits of Specialization (More, Smaller Agents): Improved accuracy on specific sub-tasks, simpler individual agent logic, better maintainability of individual agents.
Costs of Integration and Communication (More, Smaller Agents): Increased orchestration complexity, higher latency from inter-agent communication, potential for context to be lost or garbled between hops, and more complex debugging of the overall workflow.
How do you navigate this trade-off? Look for symptoms and evaluate against practical factors:
Symptoms of "Too Few" Agents (Your Agent is an Overly Monolithic "Team of One"):
Extremely Long/Complex Prompts: These are hard for anyone (including the LLM) to follow, and difficult to maintain and debug.
Consider: Factor 5 (Complexity of a Single Agent's Prompt).
Tool Ambiguity: The agent struggles to pick the right tool from many, or the prompt needs complex tool-guiding logic. \
Consider: Factor 2 (Tool Exclusivity/Minimality).
Poor Performance on Diverse Sub-Tasks: The agent excels in some areas but fails in others requiring different expertise.
Consider: Factor 1 (Task Cohesion); Factor 3 (Expertise Boundaries).
Hard to Debug: It's difficult to pinpoint the error origin within the massive prompt or broad responsibilities.
Consider: Factor 6 (Testability & Maintainability).
Updates are Risky: Changes to one part of the prompt risk unintentionally breaking other functionalities.
Consider: Factor 6 (Testability & Maintainability); Factor 7 (Lifecycle Cost).
The Overall Impact of too few agents is typically lower overall accuracy, a higher maintenance burden, slower iteration cycles, and a brittle system.
Symptoms of "Too Many" Agents (Your System is an Overly Granular "Bureaucracy"):
Excessive Inter-Agent Communication: The system becomes "chatty" with high overhead from frequent, small data exchanges.
Consider: Factor 4 (Communication Overhead vs. Internal Complexity).
Complex Orchestration Logic: The orchestrator becomes a bottleneck managing numerous tiny agents, handoffs, and sequencing.
Consider: Factor 4 (Communication Overhead); Factor 7 (Lifecycle Cost, Tolerable Overhead).
Significant Context Passing Overhead: Effort and tokens are wasted packaging and un-packaging context; there's a risk of information loss or misinterpretation.
Consider: Factor 4 (Communication Overhead).
Information Silos: Highly specialized agents lack broader context, making the synthesis of outputs difficult.
Consider: Factor 1 (Task Cohesion at a system level).
The Overall Impact of too many agents can be increased latency, higher cost, potential for reduced overall accuracy if integration is poor, and complex privacy/security management.
Practical Factors for Evaluating Your Agent Breakdown:
When deciding whether to split an agent or how to define its boundaries, the "science" involves asking yourself these kinds of questions, while the "art" involves how you weigh them based on your specific context and experience:
Task Cohesion: Do the sub-tasks an agent is currently responsible for naturally belong together? Is there a strong logical grouping, or does it feel like a grab-bag of unrelated functions? Aim for agents where sub-tasks are highly cohesive.
Tool Exclusivity/Minimality: Can an agent be defined by a relatively small, unique set of tools it needs? If an agent needs a vast and diverse toolkit, it might be trying to do too much. Look for opportunities to create agents that need only a few, very specific tools.
Expertise Boundaries: Does this agent represent a clear area of expertise that you would assign to a single human specialist or a small, focused team? If you'd need multiple distinct human experts for the tasks an agent is doing, it's a strong candidate for splitting. Think: "Is this a 'Data Analyst' agent, or is it a 'Data Analyst who also does Marketing Copy and Legal Review' agent?"
Communication Overhead vs. Internal Complexity: If splitting an agent would result in very frequent, high-bandwidth communication with another new agent for tightly coupled operations, perhaps they should remain as one (or be a very tightly coupled pair). Conversely, if keeping them as one results in an incredibly complex internal prompt to manage their interaction, splitting might be better. It's a balance, guided by experience and observation.
Complexity of a Single Agent's Prompt: Is the prompt for an agent becoming exceptionally long, difficult to reason about, or full of conditional logic to handle its various responsibilities? If your prompt is turning into a mini-book, it's a strong signal to decompose.
Testability & Maintainability: Can you easily define and test the specific responsibilities of this agent in isolation? If its tasks are too intertwined and broad, testing becomes very difficult. Aim for agents whose functionality can be clearly specified and tested independently.
Cost-Benefit per Agent (Relates to the "SPLIT" Scorecard from the 'LLM Chaining: A Pragmatic Decision Framework' article ):
Specialist Gain: Is the performance uplift from this agent being specialized (or from splitting a larger agent into this specialist) substantial and critical?
Precise Interface: Does this agent require or produce a strictly defined data schema that a more generalist approach struggles with?
Lifecycle Cost: What's the total cost (development, deployment, monitoring, latency, inference tokens) of this agent existing as a separate entity versus the benefit it provides?
Isolation Benefit: Does isolating this function into a separate agent provide significant advantages in safety, security, compliance, independent iteration, or focused fine-tuning?
Tolerable Overhead: Can the overall system tolerate the added latency, potential points of failure, and debugging complexity associated with this agent being a distinct hop in the chain?
By systematically considering these symptoms and factors, you can move from an intuitive sense of needing "multiple agents" to a more reasoned and defensible design for their granularity and responsibilities. Remember, this is an iterative process. Start with your best guess, build, observe, and then use these criteria to refine your decomposition.
The Toolkit for Building and Managing Your Agent Team
Once you've started to define your agents, assembling the right toolkit and establishing robust practices from the outset is crucial for managing their collaboration effectively and ensuring the system's long-term health. Early planning for operational aspects, including comprehensive monitoring, detailed logging, distributed tracing capabilities, and potentially tailored CI/CD pipelines for your agents, will pay significant dividends in maintainability and reliability down the line. Consider these core components:
Orchestration: This is the "project manager" or "operating system" for your agents. It can range from custom code that calls agents sequentially or based on conditional logic, to sophisticated frameworks (like LangChain, AutoGen, CrewAI), to even using another LLM as the orchestrator. The choice depends on the complexity of the interactions. OpenAI's guide discusses declarative (pre-defined graphs) vs. non-declarative (code-first, dynamic) orchestration. \
Guardrails and Safety: As the OpenAI guide emphasizes, with multiple agents interacting and potentially accessing various tools, robust guardrails are critical. \ This includes input/output validation for each agent, safety classifiers, PII filtering, and safeguards around tool use to ensure responsible and secure collaboration. \
Human Intervention Points: No autonomous system is perfect, especially in early iterations. Design clear points and mechanisms for human oversight and intervention. \ When an agent is uncertain, encounters a novel situation, or is about to take a high-risk action, it should be able to pause and escalate to a human expert. \
Decomposing a complex problem into the right set of collaborating agents is arguably one of the most challenging yet most crucial aspects of building advanced AI systems. It requires a blend of domain understanding, software architecture principles, and a pragmatic approach to iterative development.
Epilogue: Mastering the Symphony of Agents
The journey from simple LLM prompts to chained operations, and now to sophisticated multi-agent architectures, represents a significant evolution in how we build intelligent systems. We're moving from instructing a single AI to conducting a symphony of specialized agents.
The Evolving Nature of Agent Decomposition
It's crucial to remember that the "right" number of agents or the "perfect" decomposition isn't a static target you hit once and forget. It's a dynamic equilibrium that will shift:
As LLM Capabilities Advance: Future foundation models might become much better at handling a wider range of tasks with less complex prompting, potentially allowing you to consolidate agents that were previously split due to model limitations. Conversely, new specialized models might emerge that make even finer-grained, highly optimized agents feasible for specific tasks.
As Your Understanding of the Problem Deepens: The more you work with your multi-agent system and observe its performance on real-world tasks, the more insights you'll gain into better ways to structure it. You might discover new "natural" seams for decomposition or realize that some agents are too tightly coupled and should be merged.
As New Tools and Frameworks Emerge: The ecosystem around agent development is evolving rapidly. New orchestration tools, communication protocols, or debugging aids might make certain architectures easier to implement or manage, influencing your design choices.
Therefore, embrace continuous evaluation and refactoring as core practices. As advised in the 'LLM Chaining: A Pragmatic Decision Framework' article, be prepared to iterate and measure, and simplify or refactor if a component isn't justifying its existence. The same applies tenfold to multi-agent systems.
Concluding Thoughts: From Chained Steps to Intelligent Systems
Moving from linear LLM chains to dynamic multi-agent systems is a leap towards building AI that is more robust, adaptable, and capable of tackling truly complex, real-world challenges. These systems can offer specialized expertise, parallel processing, and a resilience that monolithic approaches often lack.
The art and science of decomposition lie at the heart of unlocking this potential. It's about more than just dividing tasks; it's about thoughtful design, defining clear roles and responsibilities, establishing effective communication pathways, and ensuring that the "team" of agents can collaborate coherently and safely.
Building effective multi-agent systems is a journey. It requires pragmatism to start simple, the wisdom to learn from analogies in human organizations and software architecture, the diligence to evaluate trade-offs in granularity, and the foresight to design for evolution. If you're ready to start, begin by sketching your complex problem. Identify the main tasks and sub-tasks involved and then ask yourself: "If I were building a human team for this, what distinct roles or specializations would I need?" This simple exercise can be a powerful first step in your agent decomposition journey, moving you closer to conducting true symphonies of intelligence.