
Reranking in RAG
The Secret Sauce of Precision Search

Imagine you’re on a quest for the ultimate chocolate chip cookie recipe—crispy edges, a perfectly chewy center, and just the right sweetness. You type your query into a search engine, and boom—results start pouring in. But as you scroll through the list, it quickly becomes clear: some recipes don’t quite match what you had in mind. Maybe one is crispy but brittle, another has chewy potential but misses key ingredients.
This scenario isn’t far from how modern AI search works. Fast search engines powered by vector databases cast a wide net, retrieving lots of potentially relevant information. But speed alone can’t guarantee precision. That’s where reranking models step in, carefully refining the results—just like finding the perfect recipe from an overwhelming list.
In the world of Retrieval-Augmented Generation (RAG), reranking is the magic touch that ensures AI delivers useful answers, not just plausible ones. This article explores how vector search and reranking work together to balance speed and relevance—like cookies and milk—making sure AI systems are both fast and accurate.
Casting the Net – Vector Search’s Job
Our adventure begins with a search query: “crispy chocolate chip cookies with a chewy center.”
The vector database—our quick but shallow net—jumps into action.
In seconds, it pulls a handful of documents that approximate relevance based on word embeddings and similarity scores. You get recipes A, B, and C, with scores ranging from 0.7 to 0.9.
But there’s a problem: the initial list isn’t perfect. Maybe Recipe A is ranked higher because it mentions “crispy,” but it’s a brittle cookie that doesn’t match the full intent of your query. Recipe B, which has the perfect texture, sits quietly at position two—waiting to be recognized.
This is where reranking comes in to save the day!
The Reranking Magic – It’s All in the Context
Enter the Reranking Model, a sophisticated AI that looks deeper into each candidate recipe. It understands the context of your query better than the vector search alone:
“Chewy center” is just as important as “crispy.”
It looks for alignment between query intent and document content, considering keywords, phrasing, and examples within each recipe.
Suddenly, Recipe B, initially ranked second, rises to the top spot with a score of 0.9—the perfect match!
Victory, but at a Price – Balancing Precision with Latency
The reranking model didn’t come without effort. It had to evaluate every recipe in greater depth, adding a bit of latencyto the process. This feels like baking cookies from scratch—it takes longer, but the results are worth it.
Product managers working with RAG pipelines face the same dilemma:
Do you settle for fast, but sometimes inaccurate vector search?
Or do you call in the heavy-hitting reranker for precise, context-rich answers?
While reranking improves the precision and reliability of AI systems, it also requires more compute and time. Like with cookies and milk, too much of a good thing can lead to higher costs.
The Perfect Pair – Vector Search and Reranking in RAG Pipelines
This combination of fast initial retrieval and thoughtful reranking is precisely how RAG pipelines work today. Vector search pulls the top candidates, and the reranking model ensures only the most relevant content informs the AI’s final output.
Whether it’s a customer support chatbot, an e-commerce search engine, or a legal AI assistant, reranking is the magic ingredient that turns average search results into highly relevant insights.
The Sweet Spot – Finding Balance in RAG
Much like knowing when to stop dunking your cookie in milk, product managers must find the right balance between speed and relevance. If latency or cost becomes an issue, adjusting the reranking threshold can help—perhaps only re-rank the top 10 candidates instead of 50.
In the end, the goal of RAG pipelines isn’t just to give fast answers—it’s to provide useful, relevant answers. Reranking ensures that the AI generates outputs backed by the most appropriate knowledge.
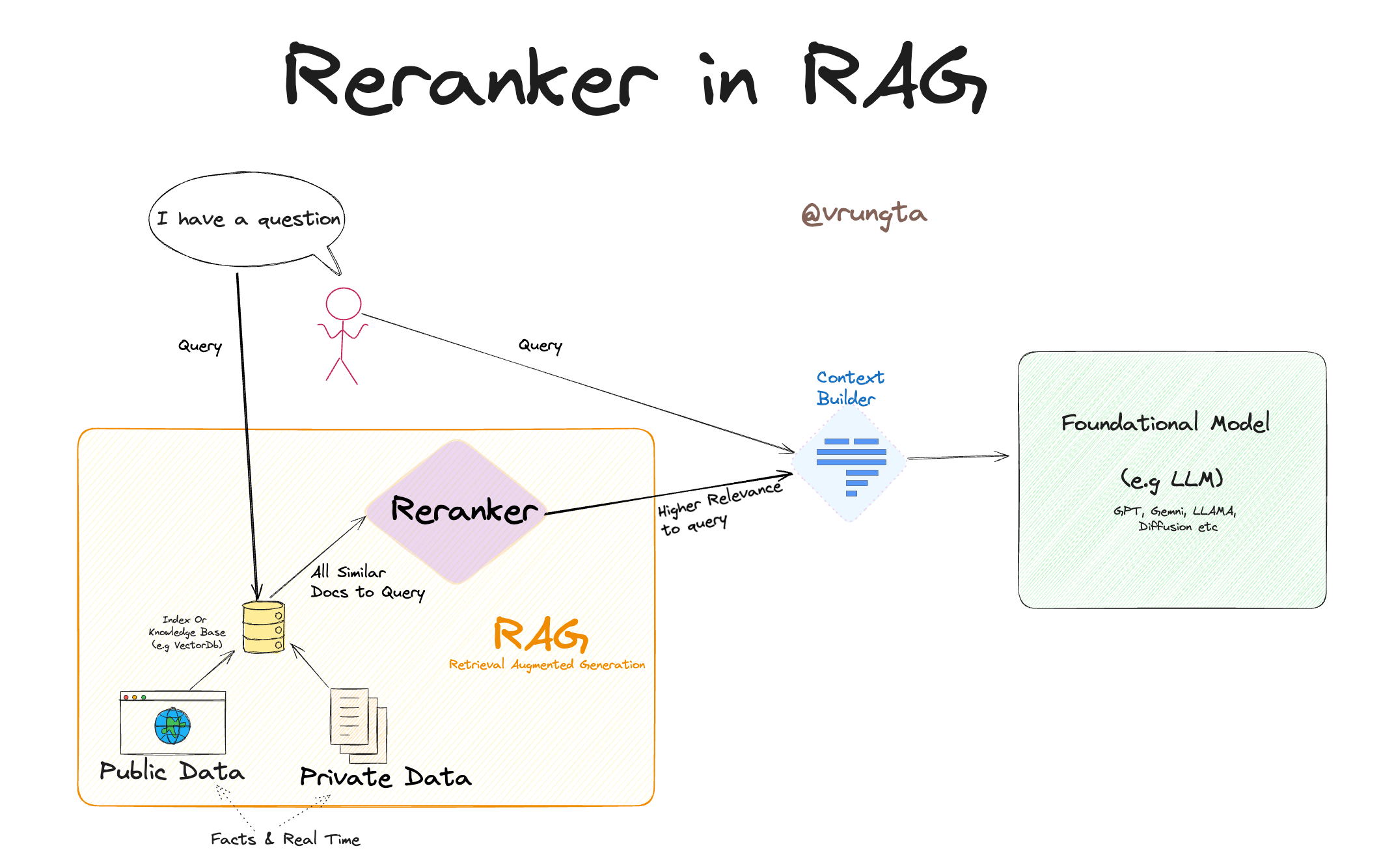
How Reranking Works: An Architectural Deep Dive
After our story, let’s now unpack how reranking works technically—making it useful for both product managers and engineers building RAG systems.
Taking Input: Query + Candidate Documents
The reranking model receives the user query and candidate documents (or passages) fetched from the vector database.
Input can be fed in either:
Separately: Each document-query pair is processed independently.
As a list: All documents are ranked relative to each other in the context of the query.
Processing with Contextual Richness
This step sets reranking apart from vector search. The model evaluates deep interactions between the query and each document.
It can use several techniques, including:
Transformer-based models (e.g., BERT, T5) that perform cross-attention between the query and documents.
Semantic matching that identifies latent connections beyond just keyword overlap.
Behavioral signals such as user click-through rates or recency of the document.
Generating Relevance Scores or Reordering the List
The model outputs either:
A relevance score for each document (higher is better).
A new order of the documents based on their relevance to the query.
Example:
Initial order:
A (0.9), B (0.8), C (0.7)Reranked order:
B (0.9), C (0.8), A (0.7)
Refining the Results
The final reranked list is what the generative model (like GPT) or search engine uses to answer the query.
This refinement step ensures that only the most relevant content is used in the AI’s response, avoiding irrelevant or incomplete results.
When to Use Reranking (and When Not To)
Use Reranking If:
You need high precision (e.g., legal research tools, medical AI systems).
Your AI outputs are critical to the user experience (e.g., customer support chatbots).
You want to minimize hallucinations by ensuring the model generates from highly relevant documents.
Skip or Limit Reranking If:
Low latency is more important than precision (e.g., search engines focused on speed).
Your cost constraints prevent you from running expensive ML models at scale.
Conclusion: Cookies, Milk, and Smarter AI Systems
Just like the perfect cookie tastes better when paired with milk, vector search and reranking are better together. One provides the speed, and the other ensures precision. This powerful combination ensures that AI-powered search systems reduce noise, enhance context, and avoid hallucinations—delivering accurate, meaningful results to users.
Whether you're building a RAG pipeline or fine-tuning a chatbot, reranking is the secret ingredient that takes AI from “just okay” to outstanding. But remember: balance is key. Use reranking wisely, balancing speed and cost against precision—because just like cookies and milk, the perfect blend makes all the difference.